Retour sur le salon Big Data & AI Paris 2022

MeltOne a eu le plaisir de participer à la 11ème édition du salon Big Data & AI Paris qui s’est tenu les 26 et 27 septembre derniers au Palais des Congrès de Paris. L’événement incontournable afin de rester au contact des nouvelles tendances technologiques et parler Data avec nos partenaires !
Qu’est-ce que le Big Data & AI Paris ?
Avec plus de 350 interventions et 250 entreprises exposantes, Big Data & AI Paris est l’événement français de référence de tout l’écosystème big data et IA qui marque le rendez-vous Tech de la rentrée.
Cette année, 16000 participants se sont réunis – en présentiel et à distance – pour discuter des actualités liées au Big Data et à l’Intelligence Artificielle. Pendant deux jours, de nombreux formats sont proposés autour de ces thèmes (conférences, ateliers, sessions tech, pitch & démos startup) et rassemblent aussi bien les acteurs historiques du marché que les jeunes startups pionnières.
A noter parmi les tendances marquantes de cette année : l’apparition des jumeaux numériques, l’utilisation de Data mesh, la notion de lakehouse, le NLP, la computer vision et speech detection, le déploiement de l’IA à l’échelle et le concept d’entreprise data-driven.

Et MeltOne alors ?
Le salon Big Data & AI Paris est un événement majeur pour MeltOne Advisory afin de nous tenir informés des dernières applications Data, Analytics, AI et BI porteuses de valeur pour nos clients et de discuter des dernières solutions de nos partenaires technologiques. C’est pourquoi l’équipe Data & Analytics a participé au salon mardi dernier afin de venir rencontrer nos partenaires (Snowflake, Alteryx, Microsoft, Dataiku, Tableau) et de s’inspirer des best practices pour mener à bien les projets de big data et d’IA à travers des conférences et retours d’expérience.
Voici ce que l’équipe a retenu du salon :
- La nouvelle solution Auto Insights d’Alteryx
Nous avons pu assister à la démonstration de la nouvelle fonctionnalité d’Alteryx « Auto Insights » sur leur stand et leur avons posé quelques questions. Auto Insights est une nouvelle solution SaaS Cloud native d’Alteryx permettant d’obtenir des insights automatisés sur une variable ciblée à partir en quelques minutes d’un simple jeu de données. Par exemple, si Auto Insights est connecté à un jeu de données de ventes, la solution peut afficher les principaux KPIs (ex : chiffre d’affaires), leur variation, les anomalies(ex : montant de vente supérieur au prix de vente) ainsi que les causes explicatives potentiellestout en donnant du contexte aux données via du data storytelling. En somme, cette nouvelle fonctionnalité facilite grandement le travail des data analysts en leur fournissant directement des insights prêts à être exploités. Par ailleurs, la connexion à Auto Insights s’établit directement avec des workflows déjà existants, ce qui réduit le temps de traitement de données du modèle.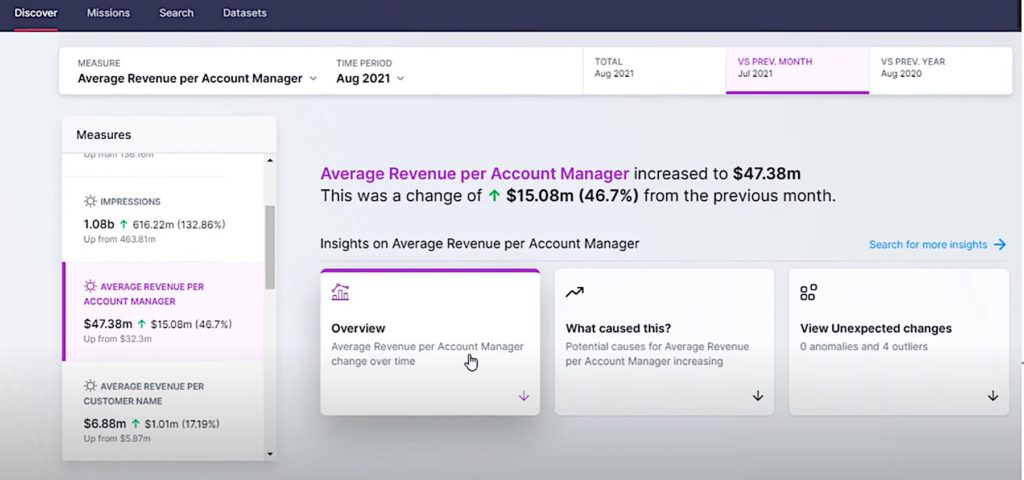
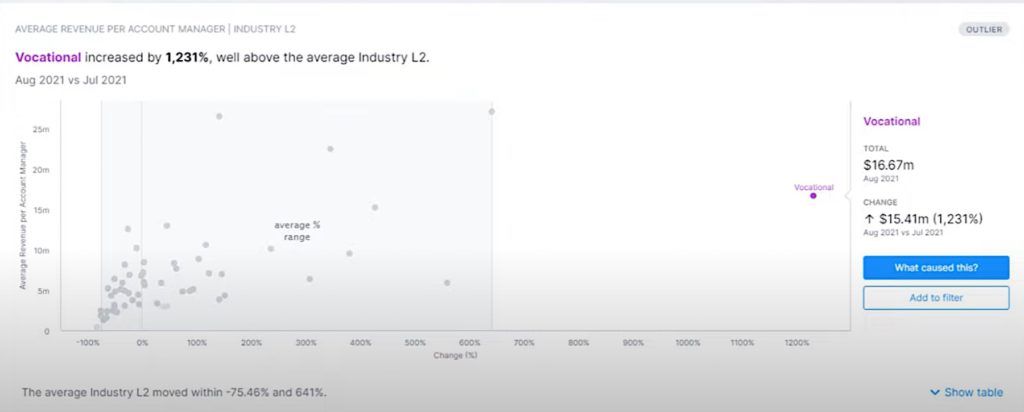
- Le passage d’un système Legacy à un Datalake Cloud (Snowflake X Believe)
Believe, leader mondial de la production musicale, a choisi Snowflake Data Cloud afin de rendre les données disponibles pour tous les collaborateursà travers le monde. Believe a migré sa Data Platform sur Snowflake en un mois durant lequel 40 milliards de lignes ont été ingérées par jour. Auparavant, les données étaient silotées et nécessitaient 8 heures de chargement pour un fichier avec 250 millions de lignes. Avec Snowflake, cette durée de chargement a été réduite à 20 minutes. Par ailleurs, Snowflake a fourni à Believe un socle technique fiableétant donné que la nouvelle Data Platformn’a jamais été en panne depuis sa mise en place. Cette Data Platform rassemble de nombreuses sources de données (données internes/externes, catalogue d’artistes, de streaming, etc.) et constitue la fondation des cas d’usage liés à l’exploitation de la donnée : Data as a Service, Data science, analytique avancée, data viz, etc.
Résultats : Single source of truth avec les données centralisées sur le Cloud, temps de chargement des données réduit, économies réalisées.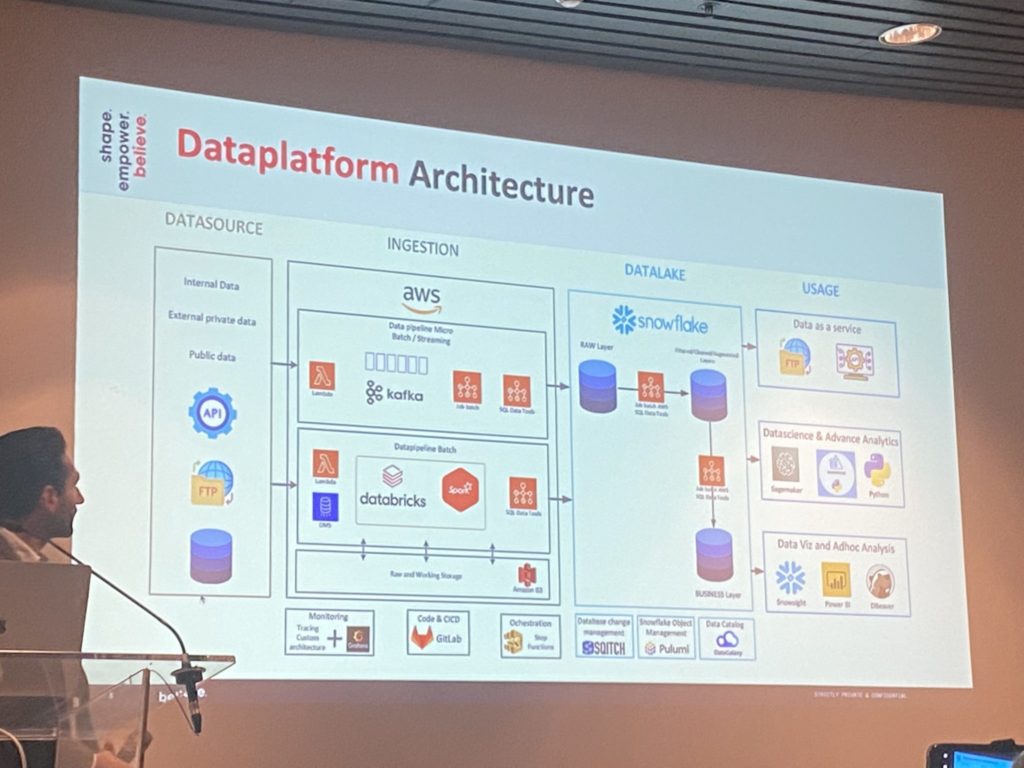
- Le Data mesh de Collibra
Le data mesh (en français « maillage de données ») est un concept qui date d’environ 3 ans. Il désigne toute architecture de données décentralisée qui organise les données par domaine d’activité spécifique. Contrairement à un système Legacy, les quatre piliers fondamentaux d’un Data Mesh sont :
– Domain ownership : Les métiers doivent s’approprier les données, notamment via des formations et une culture d’entreprise fondée autour de la donnée.
– Data as a Product : Aujourd’hui, avec une nouvelle attention portée à la gouvernance des données par les entreprises, on parle de plus en plus de Data as a Product. Par exemple, il peut s’agir de faire correspondre toute donnée à un code et une métadonnée.
– Infrastructure self-service : Une infrastructure self-service est une bibliothèque d’unités d’infrastructure approuvées qui permet à ses utilisateurs de fournir facilement des infrastructures.
– Gouvernance fédérée : Le Data Mesh regroupe chaque domaine de données qui agit comme une entité autonome au sein d’un tout.
- L’émergence de nouvelles organisations de travail autour de la donnée
– le Data Office de Collibra : Chez Collibra, le Data Office est une équipe de 8 personnes qui a pour but de permettre à l’ensemble des collaborateurs (1000 personnes) de connaître et maîtriser les données de l’entreprise. Les initiatives du Data Office incluent notamment une newsletter mensuelle, une communauté Data & Analytics, des groupes d’utilisateurs et des Data Days trimestriels. Toutes ces projets démocratisent l’analyse de données en la rendant accessible à tous et renforcent la culture data-driven de l’entreprise.
– la Data Factory du groupe LVMH : LVMH utilise Dataiku pour accompagner l’accélération et l’industrialisation de ses projets data via sa Data Factory. Cette stratégie est fondée sur 4 axes : l’innovation, les talents, l’explicabilité et le passage à l’échelle. La Data Factory de LVMH a pour but de déployer le même modèle dans l’ensemble des Maisons du groupe en produisant des algorithmes « packagés » qui peuvent ensuite être industrialisés. Ainsi, ces algorithmes peuvent répondre à des cas d’usage similaires aux différentes Maisons tels que la détection de clients potentiels/churn. Les Maisons peuvent ensuite personnaliser les caractéristiques des algorithmes packagés afin de les adapter à leurs propres besoins. Les Maisons bénéficient de formation et Dataiku fournit de la documentation technique et business aux métiers pour leur permettre d’être autonomes (exemple : Comment interpréter le score d’un modèle ?).
Résultats : livraison de cas d’usage en 3 mois, temps de mise en production réduit.
See you next year !
La période d’incertitude actuelle renforce notre besoin de comprendre le changement des enjeux de nos clients afin de mieux les accompagner, peu importe leur niveau de maturité digitale. Dans ce contexte, Big Data & AI Paris nous a ouverts à de nouvelles façons de travailler avec et autour de la donnée (Data Mesh, Data Office) ainsi qu’à des applications à forte valeur ajoutée à travers l’écosystème entier, du début de chaîne au passage à l’échelle.
Rendez-vous l’année prochaine pour Big Data & AI Paris 2023 !
N’hésitez pas à nous contacter sur jsaccona@meltone.com pour en savoir plus sur nos partenaires data.
Retrouvez l’ensemble des offres MeltOne, ERP, EPM et D&A sur notre site internet www.meltone.com.



